
In the previous article, I wrote an overview of NATS, explaining what it is, how it works, and why developers use it for building distributed systems. If you are new to NATS, I recommend reading that article first because it covers the basics like subjects, publishers, and subscribers.
In this article, let’s go a bit deeper and talk about JetStream, which is the persistence and streaming layer of NATS.
Why JetStream?
The original NATS is a lightweight messaging system. Messages are sent from publishers to subscribers, and once delivered, they are gone. This is fine for real-time communication, but in many cases, we need:
- Persistence – messages should be stored and retrievable later.
- Streaming – multiple consumers should be able to replay past messages.
- Reliability – if a consumer is offline, it should still receive messages when it comes back.
That’s where JetStream comes in.
Key Features of JetStream
- Message Persistence
- Messages are stored on disk (or memory if configured).
- You can define how long messages should live (e.g., keep for 7 days or keep the last 1,000 messages).
- Replay and Streaming
- Consumers can “rewind” and process messages from the past.
- Useful for event sourcing, reprocessing logs, or auditing.
- Durable Consumers
- Consumers can keep their position (offset) in the stream.
- If a consumer disconnects, when it comes back it will continue from where it left off.
- At-Least-Once Delivery
- JetStream ensures messages are not lost.
- Consumers acknowledge messages when processed, otherwise JetStream will redeliver them.
- Flexible Storage Options
- File-based (disk) for long-term persistence.
- Memory-based for fast but short-lived data.
How JetStream Works
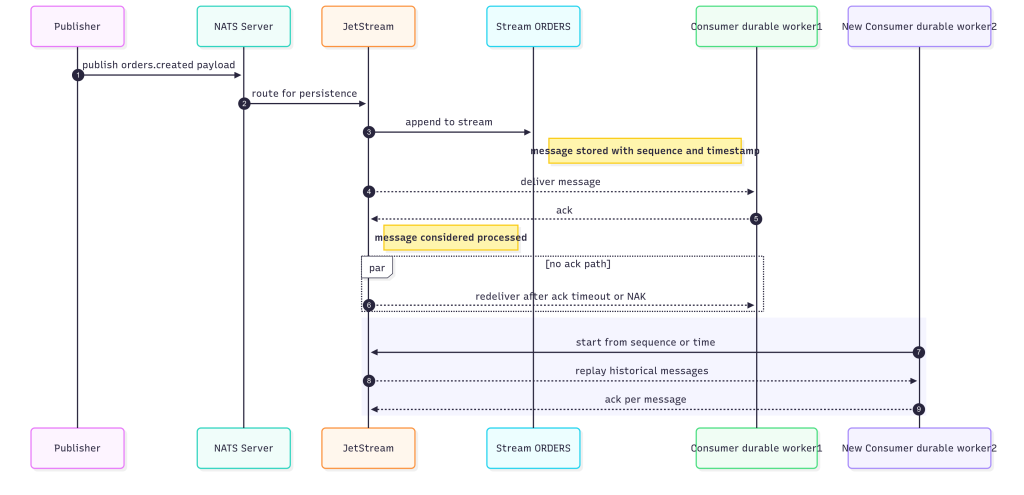
At the core of JetStream are Streams and Consumers:
- Streams – a named collection of messages stored based on a subject pattern. For example, you can have a stream that stores all messages published to
orders.*. - Consumers – subscribers that read from a stream. Consumers can be push-based (messages are delivered) or pull-based (messages are fetched on demand).
A simple flow looks like this:
- A publisher sends messages to a subject (
orders.created). - The stream
ORDERSis configured to capture that subject. - Consumers subscribe to
ORDERSand can replay or process messages as needed.
Category: NATS