
In the previous articles, we explored messaging patterns (Pub/Sub, Request–Reply, Queue Groups) and storage features (KV and Object Store) in NATS. Now let’s look at how NATS handles scalability and reliability, two critical factors when running systems in production.
Scalability in NATS
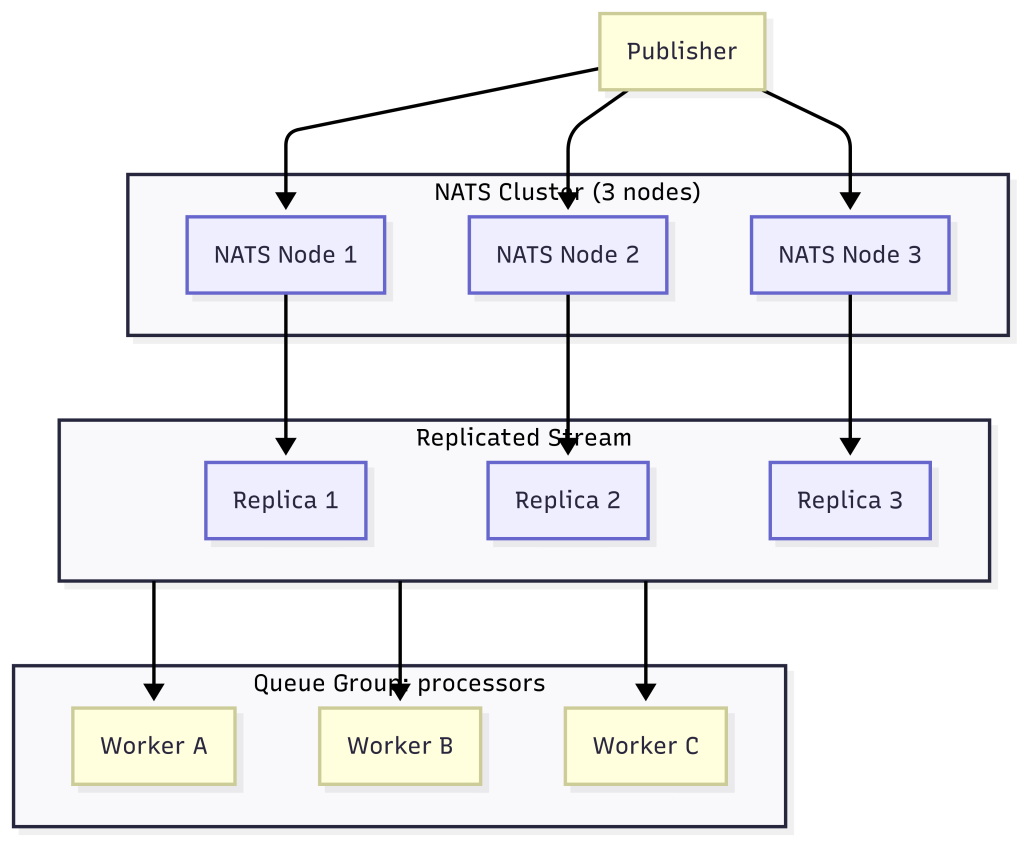
NATS is designed to be lightweight and easy to scale, both vertically and horizontally.
1. Clustering
- Multiple NATS servers can be connected in a cluster.
- Publishers and subscribers can connect to any node.
- Messages are automatically routed across the cluster.
This allows you to spread load across multiple servers instead of relying on a single node.
2. Queue Groups for Load Balancing
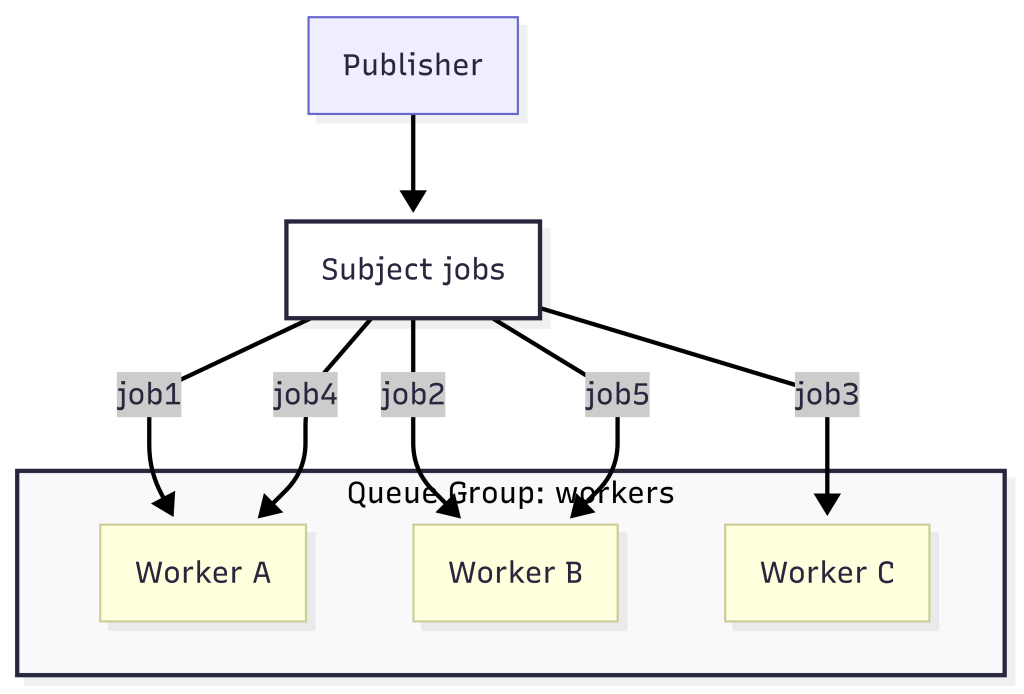
- Multiple subscribers in the same queue group share the workload.
- NATS distributes messages evenly across them.
- You can scale horizontally by simply adding more workers.
3. JetStream Scaling
- Streams can be replicated across nodes for durability.
- You can also partition subjects to distribute load.
- Consumer groups allow you to process high-throughput event streams efficiently.
Reliability in NATS
NATS provides several mechanisms to ensure reliable delivery and fault tolerance.
1. Acknowledgments (ACKs)
- In JetStream, consumers must acknowledge messages after processing.
- If no ack is received, the message is redelivered.
- This guarantees at-least-once delivery.
2. Replication
- Streams can be replicated across servers.
- If one node fails, another replica still has the data.
- This ensures messages are not lost in case of server crashes.
3. Fault Tolerance
- NATS supports superclusters (clusters of clusters) for geo-distribution.
- Clients can automatically reconnect to other servers if one becomes unavailable.
- Heartbeats and timeouts detect dead connections quickly.
4. Persistence Policies
- Limits-based retention: Keep messages up to N count, size, or age.
- Work-queue retention: Deliver each message to one consumer, then delete.
- Interest-based retention: Keep messages only while there are subscribers.
Pages: 1 2
Category: NATS