
In the last article, we talked about the NATS Key-Value Store (KV), which is great for lightweight configuration and state management. But what if you need to store something larger, like a file, image, or binary data? For that, NATS provides the Object Store, also built on top of JetStream.
What is the Object Store?
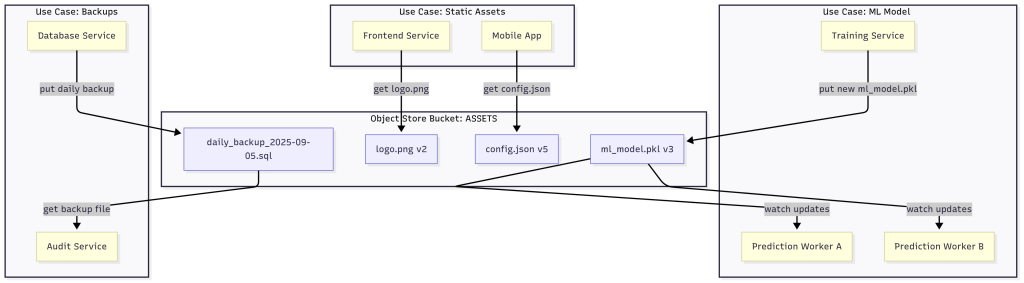
The Object Store is a way to store and retrieve large binary objects in NATS.
- Objects can be anything: documents, images, JSON files, backups.
- Each object has a name and optional metadata.
- Objects are split into chunks and stored in JetStream streams.
This makes it possible to use NATS not only for messaging, but also for managing distributed storage.
Why Use Object Store?
- Centralized Storage in Distributed Systems
- Store configuration files, ML models, or static assets directly in NATS.
- Versioned Objects
- Like KV, object store supports history of updates.
- Reactive Updates
- Other services can watch for changes and get notified when a new object version is available.
- Integration with Messaging
- Since it’s part of NATS, you can combine objects with pub/sub, request–reply, or queue groups.
NATS Object Store vs S3/MinIO
It’s natural to compare NATS Object Store with popular object storage systems like Amazon S3 or MinIO. While they share the idea of storing objects (files, blobs), their goals and strengths are different.
| Aspect | NATS Object Store | S3 / MinIO |
|---|---|---|
| Built on | JetStream (messaging + persistence) | Distributed object storage layer |
| Data size | Small to medium objects (KBs → few MBs) | Large objects (GBs → TBs) |
| Access | Through NATS clients (Go, Node.js, Python, etc.) | REST API (HTTP/HTTPS, SDKs) |
| Real-time watch | Native — services can Watch and react immediately | Not built-in; usually requires polling or event integration (like S3 Event Notifications) |
| Versioning | Built-in, with history of object updates | Supported, but more for archival and compliance |
| Integration | Tight with NATS messaging (pub/sub, KV, streams) | General-purpose storage, works independently |
| Performance | Very low-latency for distributed systems | High throughput for large-scale file storage |
| Use case | Share configs, ML models, backups inside NATS ecosystem | Store massive data sets, media files, long-term archives |
Example Perspective
- NATS Object Store:
- A machine learning team stores the latest model (
ml_model.pkl) in NATS. - Prediction workers watch the bucket and automatically reload when the model changes.
- Perfect for fast updates and small-to-medium files inside a NATS-powered system.
- A machine learning team stores the latest model (
- S3 / MinIO:
- A video platform stores user uploads (gigabytes each) in S3.
- CDN services then deliver those files to end users.
- Perfect for large-scale storage, archival, and global delivery.
Pages: 1 2
Category: NATS